- Welcome to Journal web site.
- 开发无止境 -
Data: 2021-01-13 22:41:05Form: JournalClick: 14
注:本文是以Go SDK v1.18进行讲解
注:需要写 import “strings”;
这里面都是函数,不是方法;
strings包里没有将字符串反转的函数;
以下函数会分布在string.包里的各个文件里,但是仍然还是以string.开头来;
包里的函数都不会改变原本真实值
strings.EqualFold(s,t string)bool
使用EqualFold,您可以检查两个字符串是否相等。如果两个字符串相等,则返回输出true,如果两个字符串都不相等,则返回false

strings.TrimSpace(str string) string: 去掉字符串首尾空白字符,返回字符串
strings.HasPrefix(s string, prefix string) bool: 判断字符串s是否以prefix开头
strings.HasSuffix(s string, suffix string) bool: 判断字符串s是否以suffix结尾。
strings.Index(s string, str string) int: 判断str在s中首次出现的位置,如果没有出现,则返回-1


strings.LastIndex(s string, str string) int: 判断str在s中最后出现的位置,如果没有出现,则返回-1
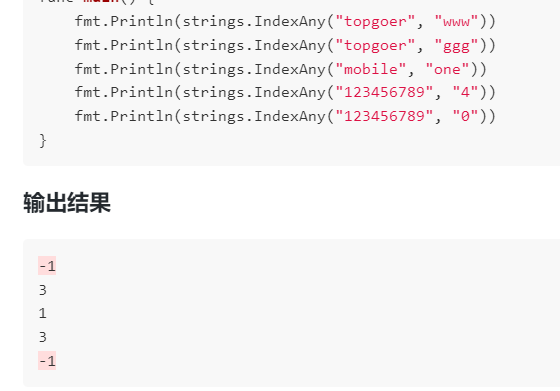
strings.IndexAny(s,chars string)int
IndexAny函数从string [left]中的chars [right]返回任何Unicode代码点的第一个实例的索引。它仅通过匹配字符串中的特定文本即可工作。如果找到,则返回以0开头的特定位置。如果找不到,则返回-1。
strings.IndexByte(s string, c byte) int
IndexByte函数返回字符串中第一个字符实例的索引。如果找到,则返回以0开头的特定位置。如果找不到,则返回-1


strings.Replace(str string, old string, new string, n int): 字符串替换
替换功能用字符串中的某些其他字符替换某些字符。n指定要在字符串中替换的字符数。如果n小于0,则替换次数数没有限制


strings.Title(s string) string
Title函数将每个单词的第一个字符转换为大写。

strings.ToTitle(s string) string将每个单词的所有字符转换为大写
注:多数情况下 ToUpper 与 ToTitle 返回值相同,但在处理某些unicode编码字符则不同(暂时不用管)

strings.ToLower(str string) string: 将每个单词的所有字符转换为小写

strings.ToUpper(str string) string: 将每个单词的所有字符转换为大写


strings.Contains(s, substr string) bool: 判断字符串s是否包含子串substr。

strings.ContainsAny(s,chars string)bool
判断字符串s是否包含字符串chars中的任一字符。



strings.IndexRune(s string, r rune) int
IndexRune函数以字符串形式返回Unicode代码点r的第一个实例的索引。如果找到,则返回以0开头的特定位置。如果找不到,则返回-1。在下面的示例中,s,t和u变量类型声明为符文

strings.Count(s, sep string) int: 返回字符串s中有几个不重复的sep子串。
此函数计算字符串中字符/字符串/文本的不重叠实例的数量。

![]()
strings.Repeat(str string, count int)string: 重复count次str
Repeat函数将字符串重复指定的次数,并返回一个新字符串,该字符串由字符串s的计数副本组成。Count指定将重复字符串的次数,必须大于或等于0

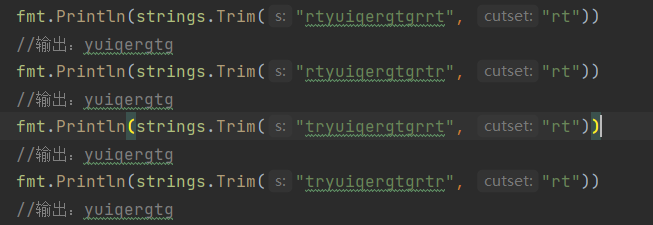
strings.Trim(str string, cut string): 去掉字符串首尾cut字符
trimlefit函数只从字符串s的左侧删除预定义字符cutset。

strings.TrimLeft(str string, cut string): 去掉字符串首cut字符

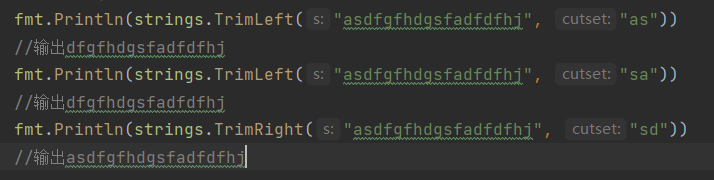
strings.TrimRight(str string, cut string): 去掉字符串首cut字符

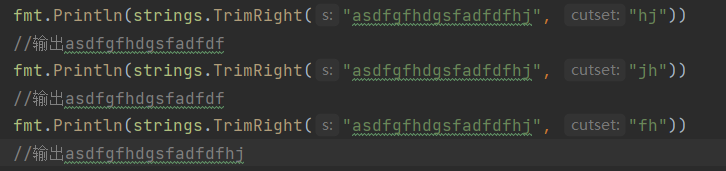
strings.TrimPrefix(S string, prefix string) string
TrimPrefix函数从S字符串的开头删除前缀字符串。如果S不以前缀开头,则S将原封不动地返回

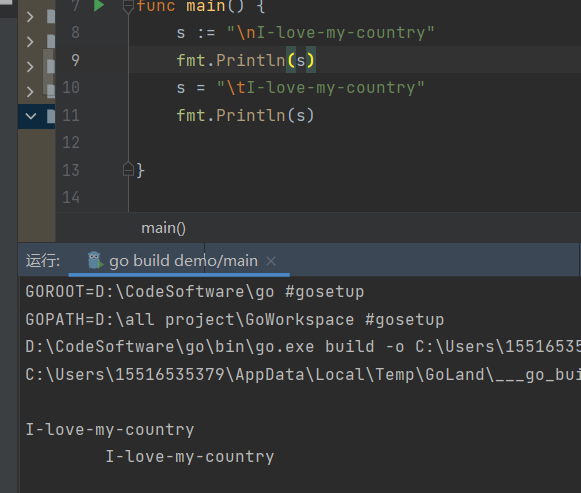
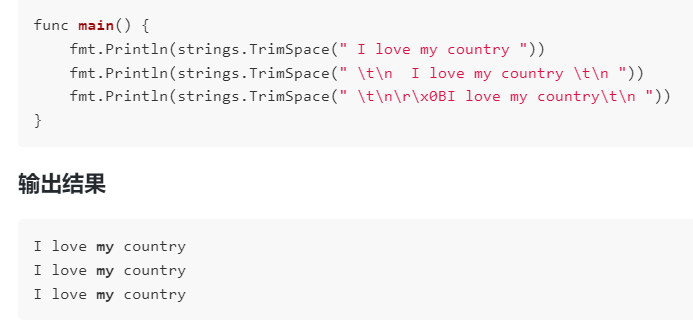
TrimSpace函数从字符串的两侧删除空白和其他预定义字符
strings.TrimSpace(s string) string
“\t”-选项卡
“\n”-新行
“\x0B”-垂直选项卡
“\r”-回车
“”-普通空白
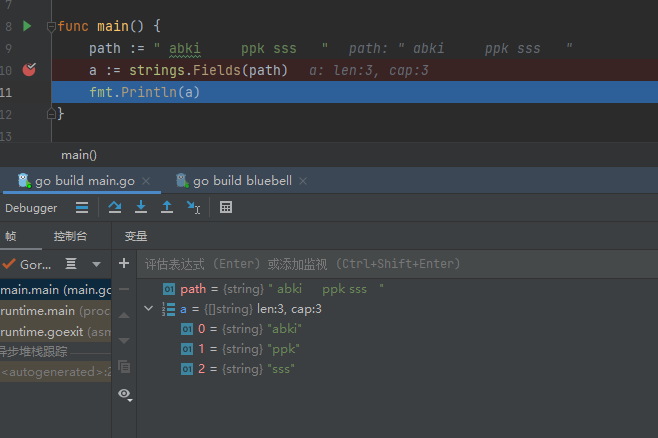
strings.Fields(str string) []string : 返回str空格分隔的所有子串的slice,
Fields函数将一个或多个连续空白字符的每个实例周围的字符串分解为一个切片


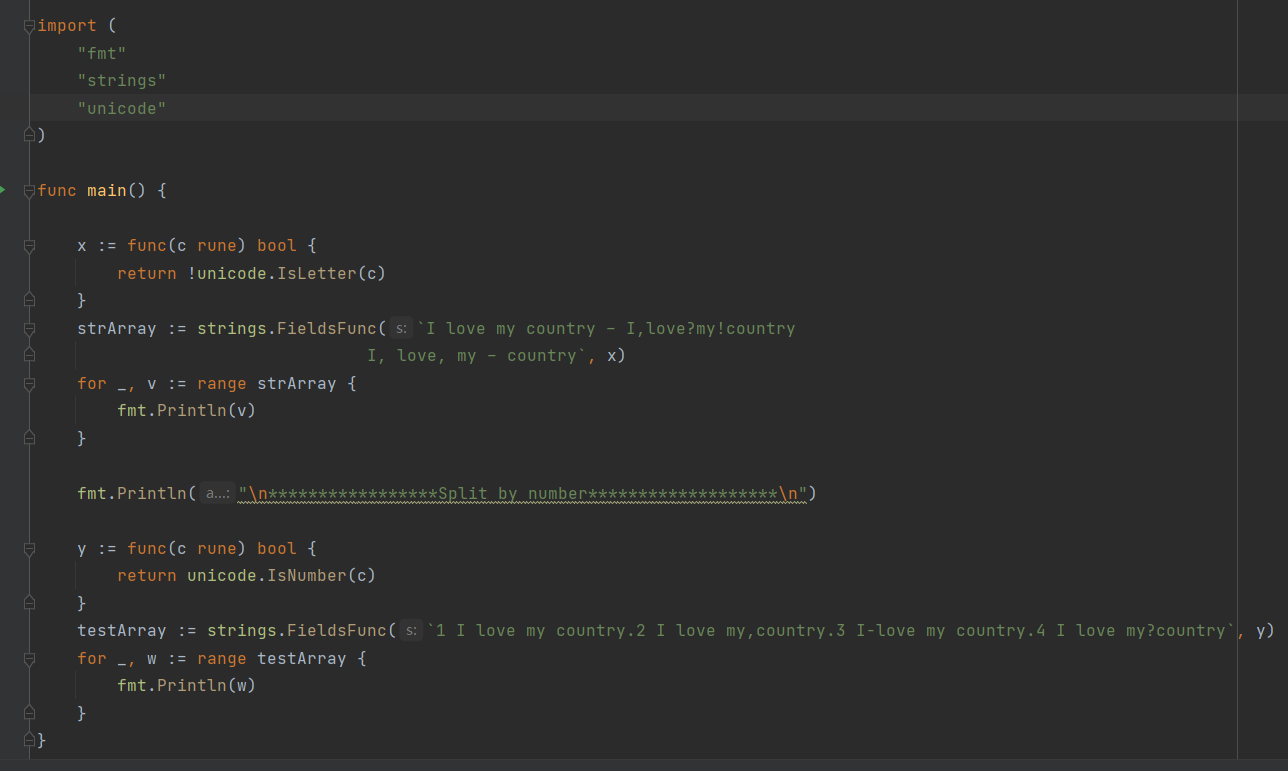
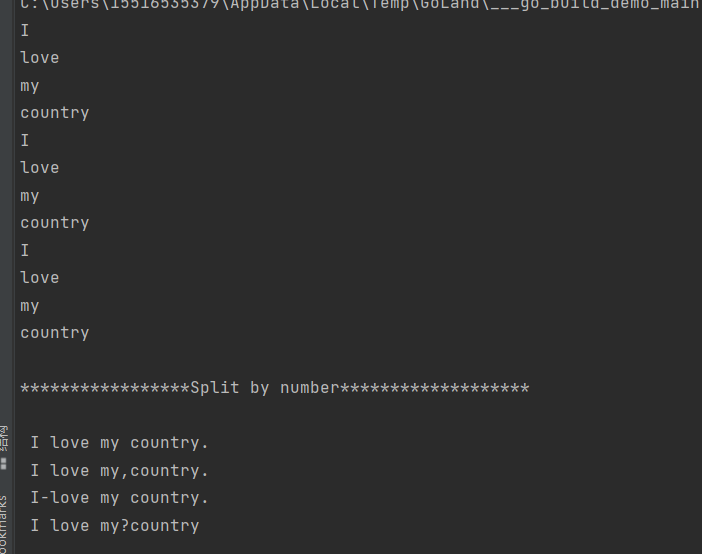
strings.FieldsFunc(s string,f func(rune bool)[] string
FieldsFunc函数在每次运行满足f(c)的Unicode代码点c时都将字符串s断开,并返回s的切片数组。您可以使用此功能按数字或特殊字符的每个点分割字符串
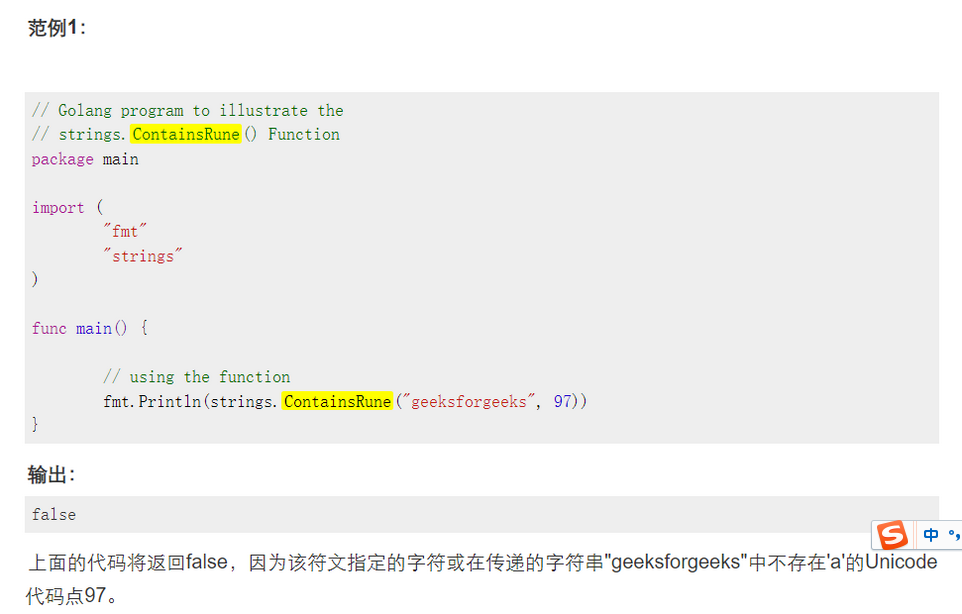
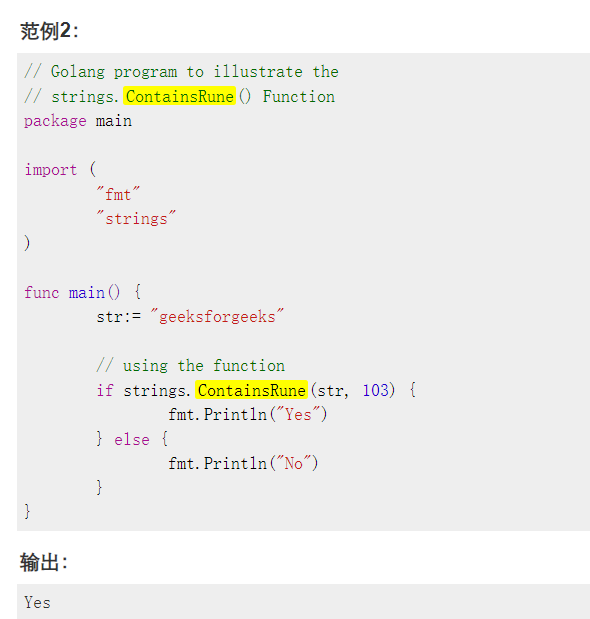
strings.ContainsRune(s string, r rune) bool: str是字符串,r是s符文,如果字符串中存在由符文指定的字符,则它将返回布尔值true,否则返回false
ContainsRune()Golang中的函数用于检查给定的字符串是否包含指定的符文
Unicode是ASCII的超集,包含世界上书写系统中存在的所有字符,是目前正在遵循的字符集。Unicode系统中的每个字符都由Unicode代码点唯一标识,该代码点在Golang中称为符文
介绍
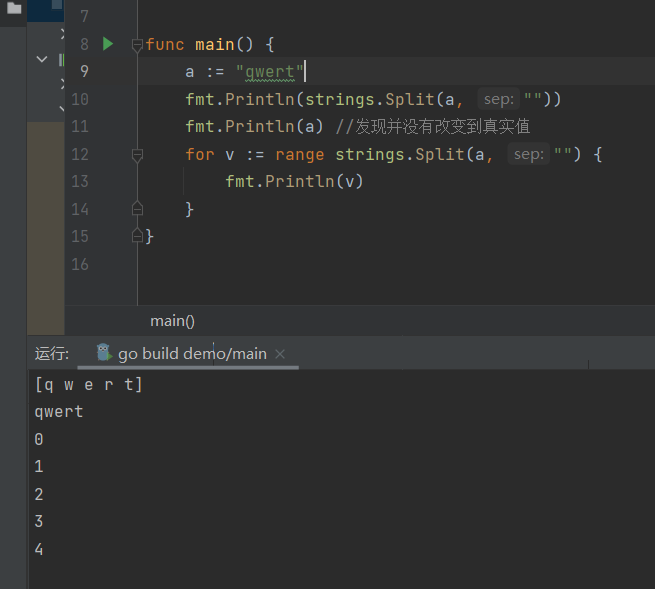
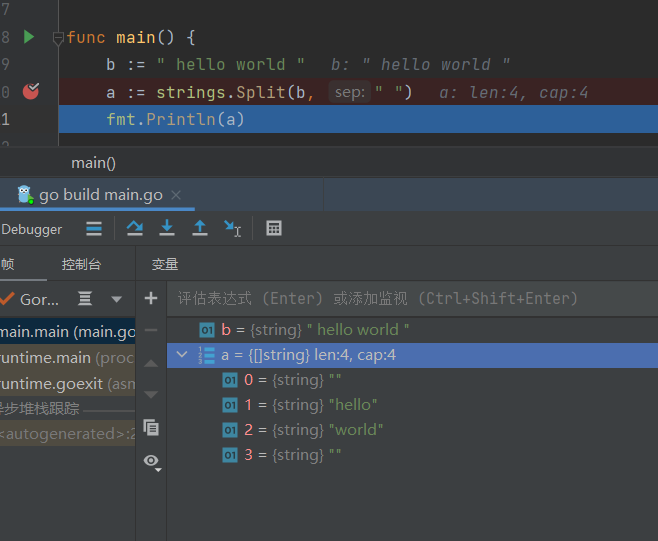
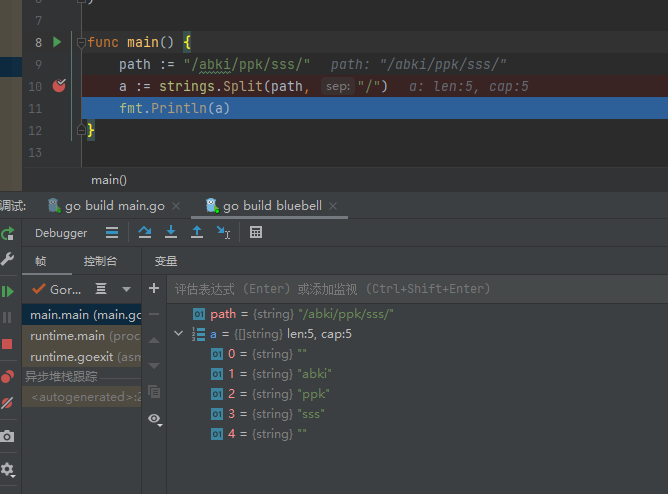
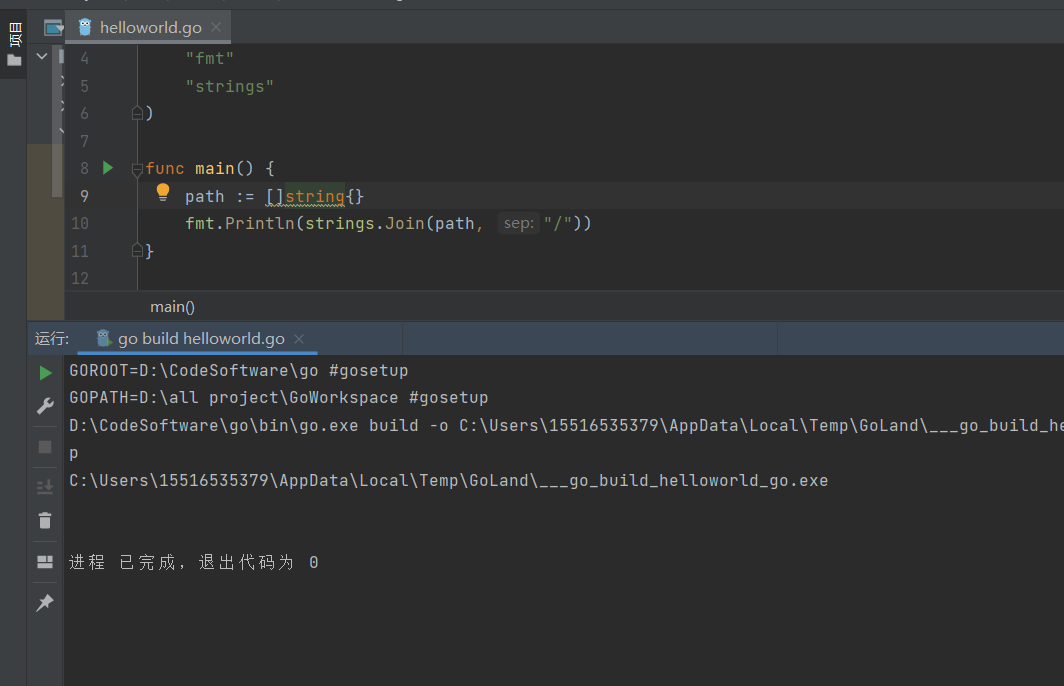
strings.Split(str string, split string) []string : 返回str split分隔的所有子串的slice

切割空字符串
两边有字符串的情况
正常情况

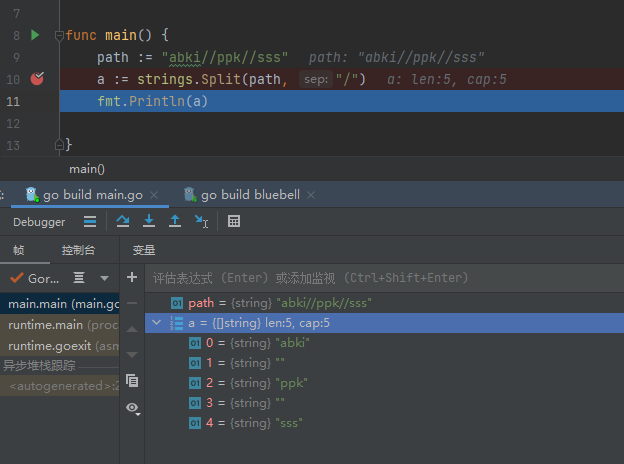
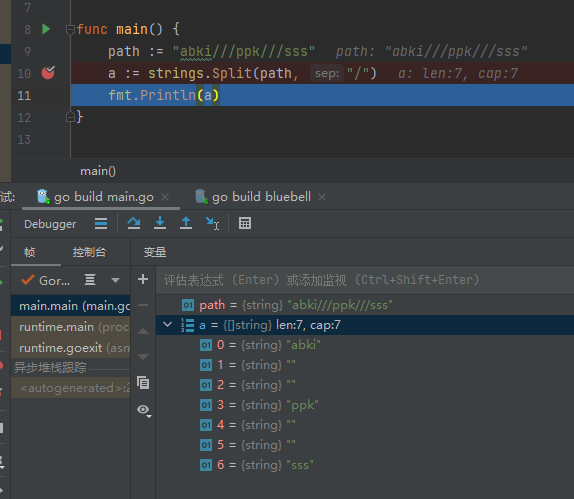
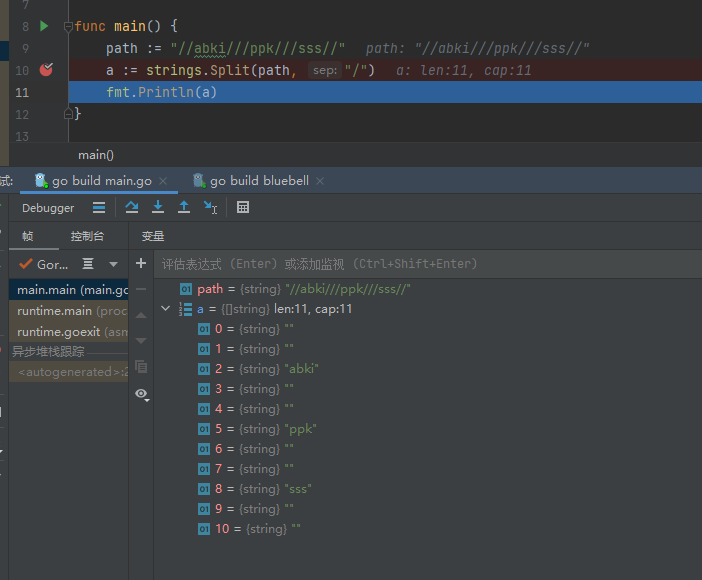
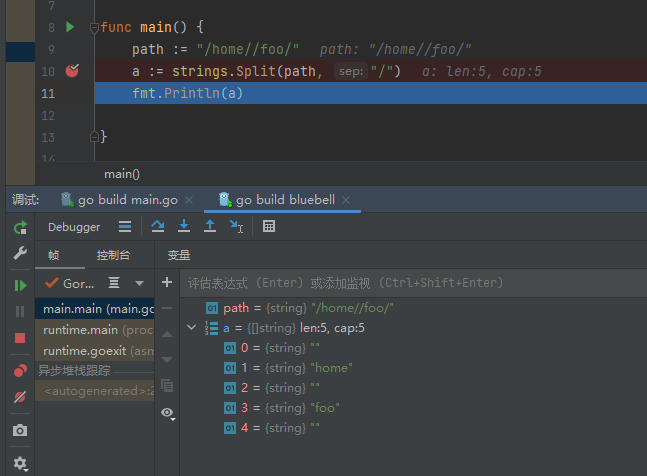

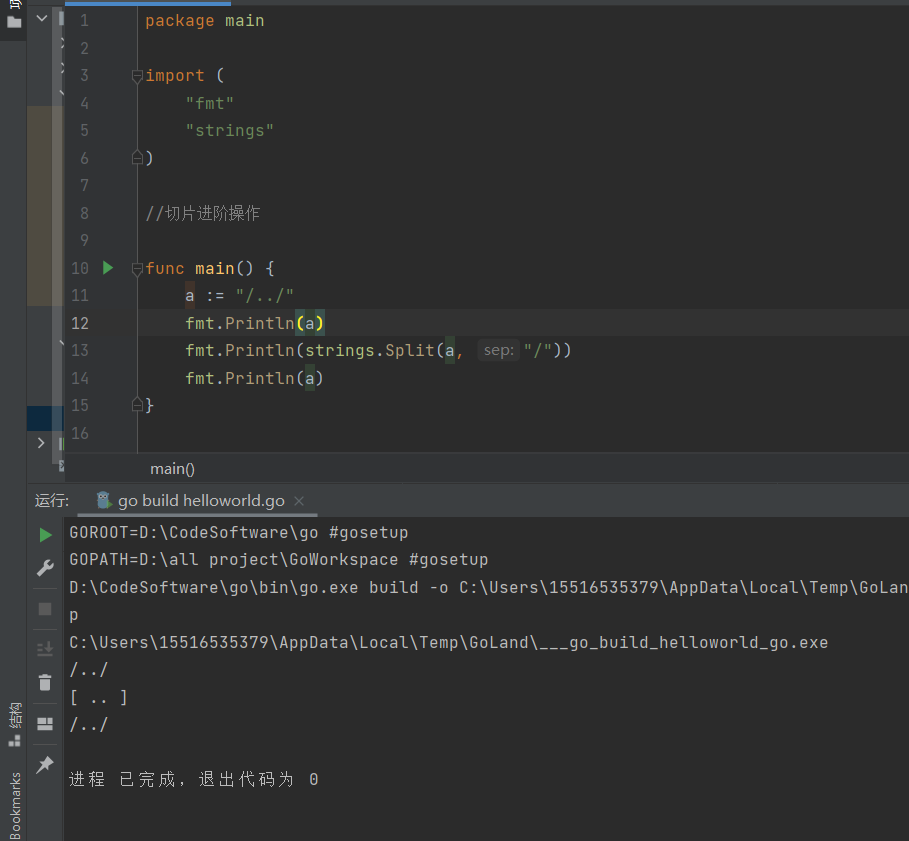

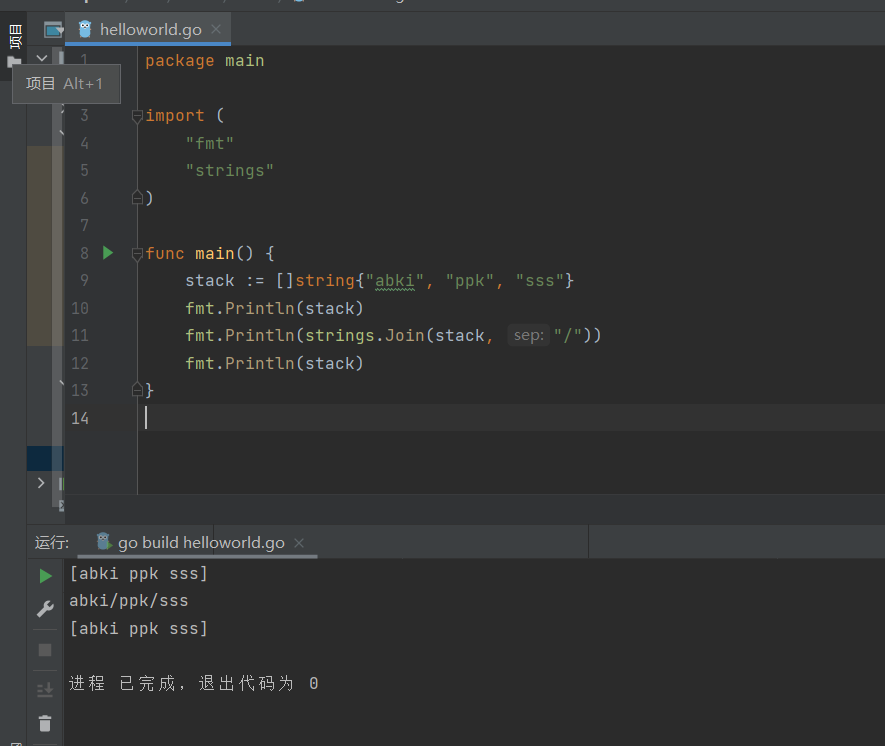
strings.Join(s1 []string, sep string) string : 用sep把s1中的所有元素链接起来 ,并返回字符串

package main
import (
"strings"
"fmt"
)
func main() {
read := strings.NewReader("大家好我是刘")
fmt.Println(read.Len()) //返回未读取的长度 ; 输出 : 18
// Go 语言的字符串都以 UTF-8 格式保存,每个中文占用 3 个字 节,因此使用 len() 获得6个中文文字对应的18个字节。
fmt.Println(read.Size()) //返回字符串的长度 ; 输出 :18
buff := make([]byte, 18) //开辟空间为后面的读取用,这里我用18,其实可以直接用rea.Len() 或者read.Size()
read.Read(buff) //通过指定的空间,读取指定长度的数据
fmt.Println("中文字符串:", string(buff)) //打印空间中的内容 ; 输出 : 中文字符串: 大家好我是刘
buffAt := make([]byte, 18)
read.ReadAt(buffAt, 3) //读取第三字节以后的数据, 注意啊,这里的如果不是3,6,9之类的,会出现方框.以这个中文3字节码!
enRead := strings.NewReader("abcdefghijk")
b, _ := enRead.ReadByte() //向后读取一个字节,这里是中文所有会输出方框,可以用英文
b, _ = enRead.ReadByte() //再向后读取一个字节,这里是中文所有会输出方框,可以用英文
b, _ = enRead.ReadByte() //再向后读取一个字节,这里是中文所有会输出方框,可以用英文
fmt.Println("英文字符串:", string(b)) //输出:英文字符串: c
fmt.Println(int(enRead.Size()) - enRead.Len()) //通过总字节数-还剩字节数,计算读了多少字节
//输出 : 3
enRead.UnreadByte() //向前一个字节
fmt.Println(int(enRead.Size()) - enRead.Len()) //通过总字节数-还剩字节数,计算读了多少字节
//输出 : 2
}
strings.SplitN(s, sep string, n int) []string
用去掉s中出现的sep的方式进行分割,会分割到结尾,并返回生成的所有片段组成的切片(每一个sep都会进行一次切割,即使两个sep相邻,也会进行两次切割)。如果sep为空字符,Split会将s切分成每一个unicode码值一个字符串。参数n决定返回的切片的数目:
n > 0 : 返回的切片最多n个子字符串;最后一个子字符串包含未进行切割的部分。
n == 0: 返回nil
n < 0 : 返回所有的子字符串组成的切片


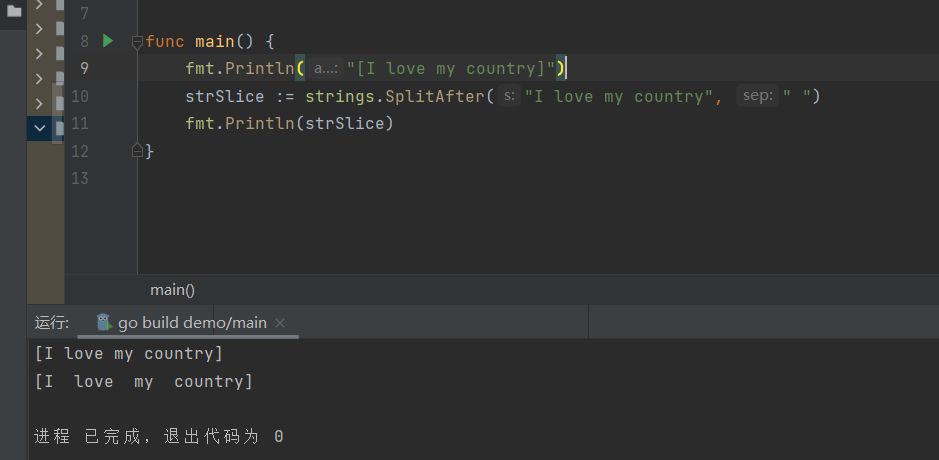
strings.SplitAfter(S String, sep string) []string
用从s中出现的sep后面切断的方式进行分割,会分割到结尾,并返回生成的所有片段组成的切片(每一个sep都会进行一次切割,即使两个sep相邻,也会进行两次切割)。如果sep为空字符,Split会将s切分成每一个unicode码值一个字符串。


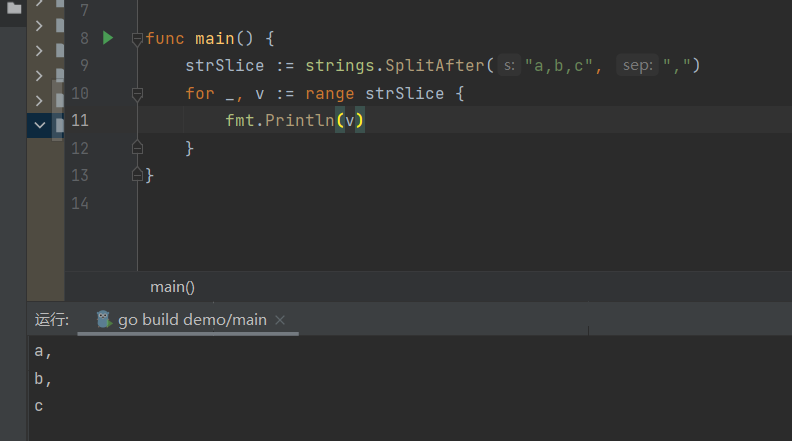
strings.SplitAfterN(string s, sep string, n int) []string
SplitAfterN函数将字符串分成片。SplitAfterN在sep的每个实例之后将String切片为子字符串,并返回这些子字符串的切片。n确定要返回的子字符串数。
n > 0 : 返回的切片最多n个子字符串;最后一个子字符串包含未进行切割的部分。
n == 0: 返回nil
n < 0 : 返回所有的子字符串组成的切


func Cut(s, sep string) (before, after string, found bool)
将字符串 s 在第一个 sep 处切割为两部分,分别存在 before 和 after 中。如果 s 中没有 sep,返回 s,“”,false
func main() {
addr := "192.168.1.1:8080"
ip, port, ok := strings.Cut(addr, ":")
fmt.Println(ip)
fmt.Println(port)
fmt.Println(ok)
/*疏输出:
192.168.1.1
8080
true
*/
}
//如果没有cut函数,则使用下面的方法
addr := "192.168.1.1:8080"
pos := strings.Index(addr, ":")
if pos == -1 {
panic("非法地址")
}
ip, port := addr[:pos], addr[pos+1:]
func Index(s, substr string) int
func IndexAny(s, chars string) int
func IndexByte(s string, c byte) int
func IndexFunc(s string, f func(rune) bool) int
func IndexRune(s string, r rune) int
func LastIndex(s, substr string) int
func LastIndexAny(s, chars string) int
func LastIndexByte(s string, c byte) int
func LastIndexFunc(s string, f func(rune) bool) int
日常编程中,字节 []byte 是经常需要复制的。需要写以下代码:
dup := make([]byte, len(data))
copy(dup, data)
觉得这就太麻烦了,毕竟每次都得写一遍,又或是自己封装成如下函数:
// Clone returns a copy of b
func Clone(b []byte) []byte {
b2 := make([]byte, len(b))
copy(b2, b)
return b2
}
熟悉语法的同学还会有以下的方式,
b2 := append([]byte(nil), b...)
许多 Go 开发者,在写应用程序要复制切片(Slice)时,会发现复制出来的切片 s1 和原始的 s0 有内存上的关联,其本质原因在于其底层的数据结构导致,这会导致许多隐藏的问题。
示例代码如下:
func main() {
s0 := "脑子进煎鱼了"
s1 := s0[:3]
fmt.Println(s0) //脑子进煎鱼了
fmt.Println(s1) //脑
s0h := (*reflect.StringHeader)(unsafe.Pointer(&s0))
s1h := (*reflect.StringHeader)(unsafe.Pointer(&s1))
fmt.Printf("Len is equal: %t\n", s0h.Len == s1h.Len) //Len is equal: false
fmt.Printf("Data is equa: %t\n", s0h.Data == s1h.Data) //Data is equa: true
}
Len 不相等,毕竟是按索引复制的。但 Data 竟然就相等了,这为什么,是 Go 出 BUG 了吗?
这实际是与 Go 在 String 和 Slice 的底层数据结构有关的,例如 String 的运行时表现是 StringHeader。
他的底层结构如下:
Data:指向具体的底层数组。
Len:代表字符串切片的长度。
type StringHeader struct {
Data uintptr
Len int
}
关键就在于 Data,本质上是一个指向底层数据的指针地址,因此在复制时,会将其也复制过去。造成不必要的复制和 “脏” 数据,引发各种奇怪的 BUG。
在 Go1.18 的新特性中,strings 和 bytes 增加了一个 Clone 方法,来解决前面提到的 2 个问题点。
源代码如下:
通过 copy 函数对原始字符串进行复制,得到一份新的 []byte 数据。
通过 *(*string)(unsafe.Pointer(&b)) 进行指针操作,实现 byte 到 string 的零内存复制转换。
func Clone(s string) string {
if len(s) == 0 {
return ""
}
b := make([]byte, len(s))
copy(b, s)
return *(*string)(unsafe.Pointer(&b))
}