一 索引原理
如果一本新华字典假如没有目录,想要查找某个字,就不得不从第一页开始查找,一直找到最后一页(如果要找的字在最后一页),这个过程非常耗时,这种场景相当于数据库中的全表扫描的概念,也就是循环表中的每一条记录看看该记录是否满足条件,扫描次数为表的总记录数。
新华字典中都会有目录都有查找方法(比如按拼音查找、按部首查找),假如按拼音查找,我们根据拼音就能瞬速定位到要找的汉字,而这个汉字后面还有这个汉字对应的页数,我们直接翻到该页就能找到,整个查找过程非常快,用时非常短。这个原理就是数据库中索引的原理。这里的按拼音查找、按部首查找是两种不同的查找方式,通过每种方式都能快速找到,在数据库中也有很多查找方式,称之为索引方法,有BTREE、HASH两种方式
BTREE:一颗倒立的树,每个节点都有父节点,父节点下面的节点称之为子节点(叶子节点),比父节点值小的位于父节点下面的左方,比父节点值大的子节点放置在父节点下面的右下方。
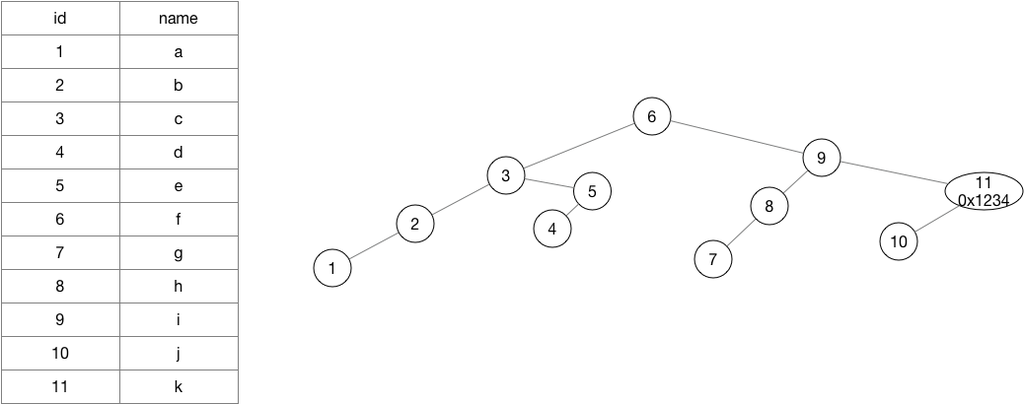
记录索引列的值和对应的记录所在的磁盘位置,每次排除掉一半, 检索一次相当排除掉2的n次幂,使用二叉树排除30次相当于全表排除10亿次。比如查询id=11的值,首先和6比,比6大就排除掉左边的,继续和9比较,11比9大,又排除掉左边的一般,和11进行比较,相等就找到了结果。当数据量很大的时候,每次都排除掉一半,排除的数据量是非常惊人的。
Hash:Hash索引只能等值匹配,想范围查询,左前缀查询都不适用, 其余大部分场景
为什么要使用索引?
- 索引大大减少了存储引擎需要扫描的数据量
- 索引可以帮助我们进行排序以避免使用临时表
- 索引可以把随机IO变为顺序IO
二 索引类型
- 主键索引(primary key):添加了主键就有了主键索引,可以在创建表的时候指定主键,也可以在创建成功之后再增加
- 唯一索引(unique):添加了唯一约束就有了唯一索引,唯一索引可以有多个null
- 普通索引(normal):一般是先建表,后面再创建索引,普通索引使用的最多
- 全文索引(fulltext):主要针对文本段落等,全文索引只能应用MyISAM引擎
- 空间索引(spatial): 使用较少,并且mysql支持的还不好
关于唯一性有两种做法:
- 通过程序来保证数据的唯一性
- 业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。 说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。(来自阿里巴巴Java开发手册)
关于全文索引:
全文索引只能用于MyISAM引擎,通常如果用到全文索引一般通过Elasticsearch、Solr、Lucene等技术来实现。
三:索引语法
1. 创建索引
①:语法
-- 创建普通索引:
create index 索引名 on 表(列1【ASC|DESC】, 列2 ASC|DESC】)
-- 创建唯一索引
create unique index on 表名(列名) 查询没有使用到的索引
SELECT
object_schema,
object_name,
index_name,
b.table_rows
FROM performance_schema.table_io_waits_summary_by_index_usage a
JOIN information_schema.tables b ON a.object_schema = b.table_schema AND a.object_name = b.table_name
WHERE index_name IS NOT NULL
AND count_star = 0
ORDER BY object_schema, object_name;