- Welcome to Journal web site.
- 开发无止境 -
Data: 2021-05-21 16:56:00Form: JournalClick: 26
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。在高负载的情况下,添加更多的节点,可以保证服务器性能。MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
0.操作命令
1.连接
(1)完整
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
(2)使用默认端口
mongodb://localhost
(3)使用shell
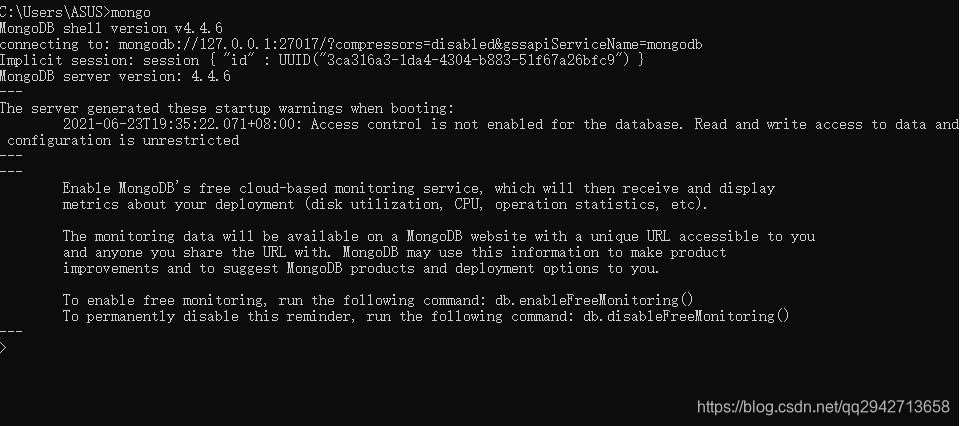
mongo
2.查询数据库
(1)查询所有数据库
show dbs

3.创建数据库
use database_name
如果数据库不存在,则创建并切换到该数据库,存在则切换到该数据库
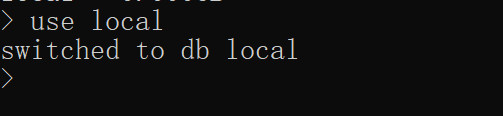
(1)已存在
\
(2)不存在
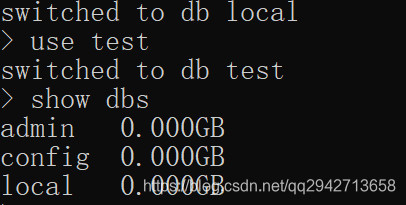
可以看到,创建的 test数据库并没有显示,需要插入数据才能显示
\
4.删除数据库
先切换到指定数据库,然后执行以下命令
db.dropDatabase()
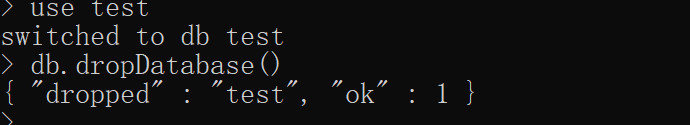
1.创建集合
切换到指定数据库,然后执行如下命令
db.createCollection(name, options)
说明:
name 要创建的集合名称,可选参数,指定有关内存大小及索引的选项
options参数:capped如果为true则创建固定集合(有着固定大小的集合);size为固定集合指定一个最大值,如果capped为true需要指定该字段;max 指定固定集合中包含文档的最大数量

带参数的集合

插入文档会自动创建集合

2.查看所有集合
先切换到指定数据库,然后执行如下命令
show collections

3.删除集合
db.COLLECTION_NAME.drop()
成功删除则返回true,否则返回false
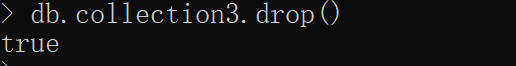
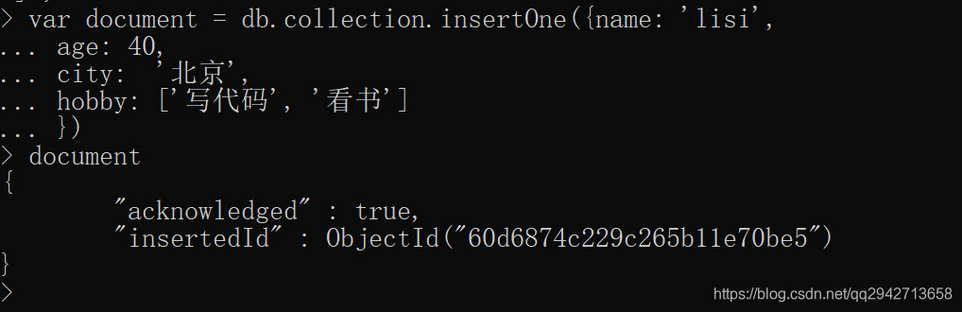
1. 插入文档
使用insert()或insertOne()或insertMany()方法插入文档
db.COLLECTION_NAME.insert(document)

插入单条数据
db.collection.insertOne(
<document>,
{
writeConcern: <document>
}
)
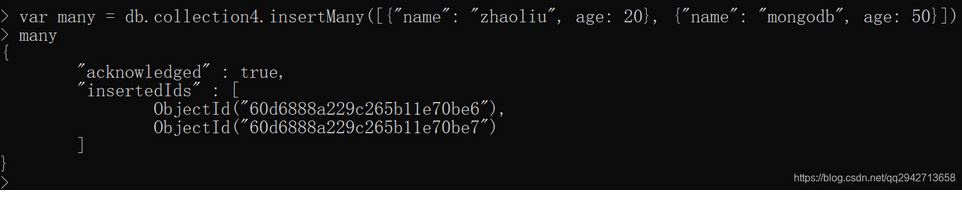
插入多条数据
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
document: 要写入的文档
writeConcern:写入策略,默认为1,即要求默认写操作,0是不要求
ordered:是否按照顺序写入,默认为true,按照顺序写入
shell默认使用64位浮点型数值,如下:
db.sang_collec.insert({x:3.1415926})
db.sang_collec.insert({x:3})
db.sang_collec.insert({x:NumberInt(10)})
db.sang_collec.insert({x:NumberLong(12)})
db.sang_collec.insert({x:[1,2,3,4,new Date()]})
MongoDB支持Date类型的数据,可以直接new一个Date对象,如下:
db.sang_collec.insert({x:new Date()})
value,这个其实很好理解,如下:
db.sang_collect.insert({name:"三国演义",author:{name:"罗贯中",age:99}});
书有一个属性是作者,作者又有name,年龄等属性。
2.查询文档
db.COLLECTION_NAME.find(query, projection)
pretty()以格式化方法显示文档
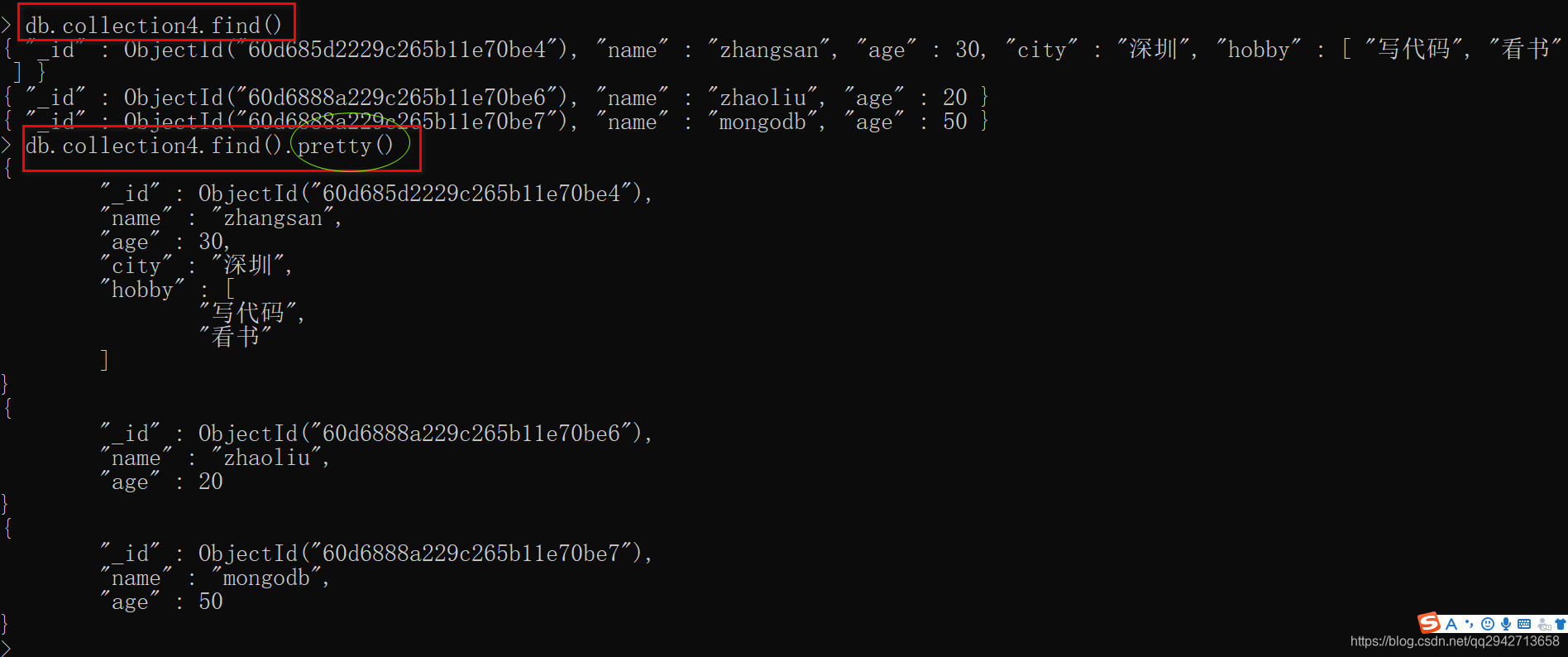
模糊搜索
db.users.find({fname: /zhangsan/});
对应mysql的like用法:select * from users where fname like '%zhangsan%';
(1)如果要模糊查询以什么开头,方法如下:
db.users.find({fname: /^zhangsan/});
(2)如果要模糊查询以什么结尾,方法如下:
db.users.find({fname: /zhangsan^/});
3.更新文档
使用update()和save()方法来更新集合中的文档
(1)update()方法
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
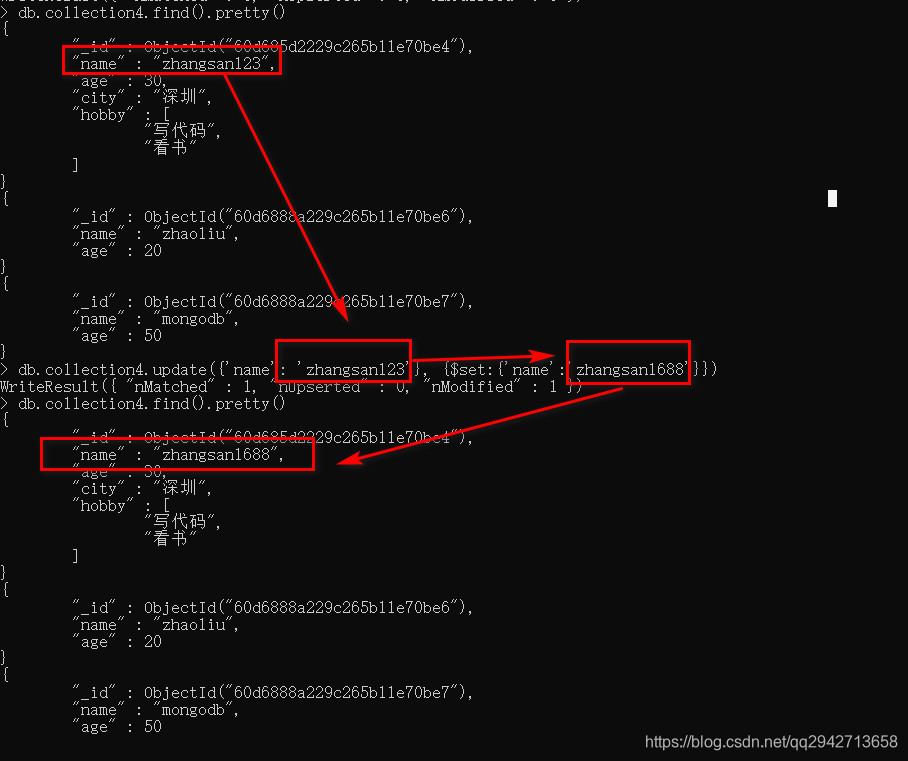
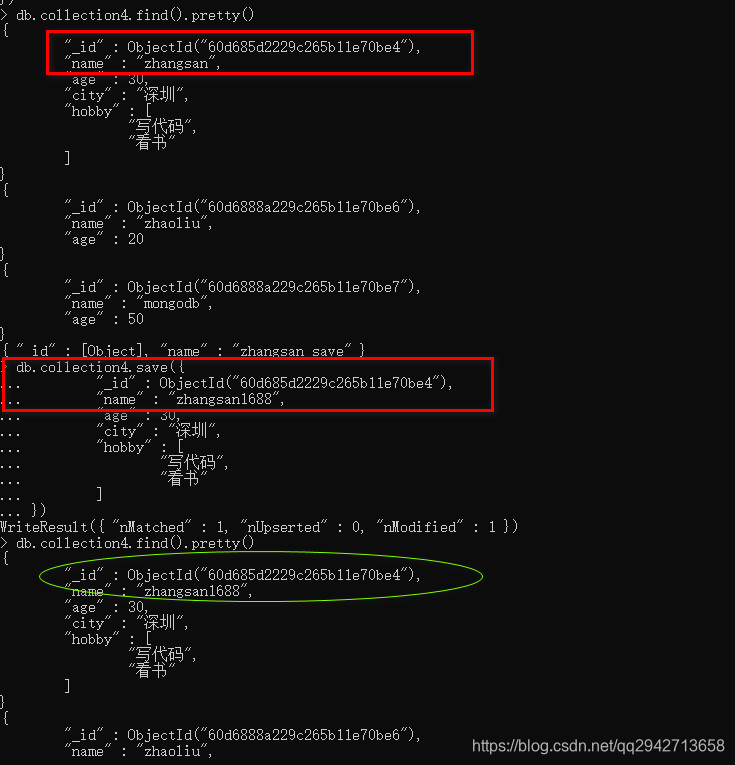
(2)save()方法
save() 方法通过传入的文档来替换已有文档,_id 主键存在就更新,不存在就插入。
db.collection.save(
<document>,
{
writeConcern: <document>
}
)
参数说明:
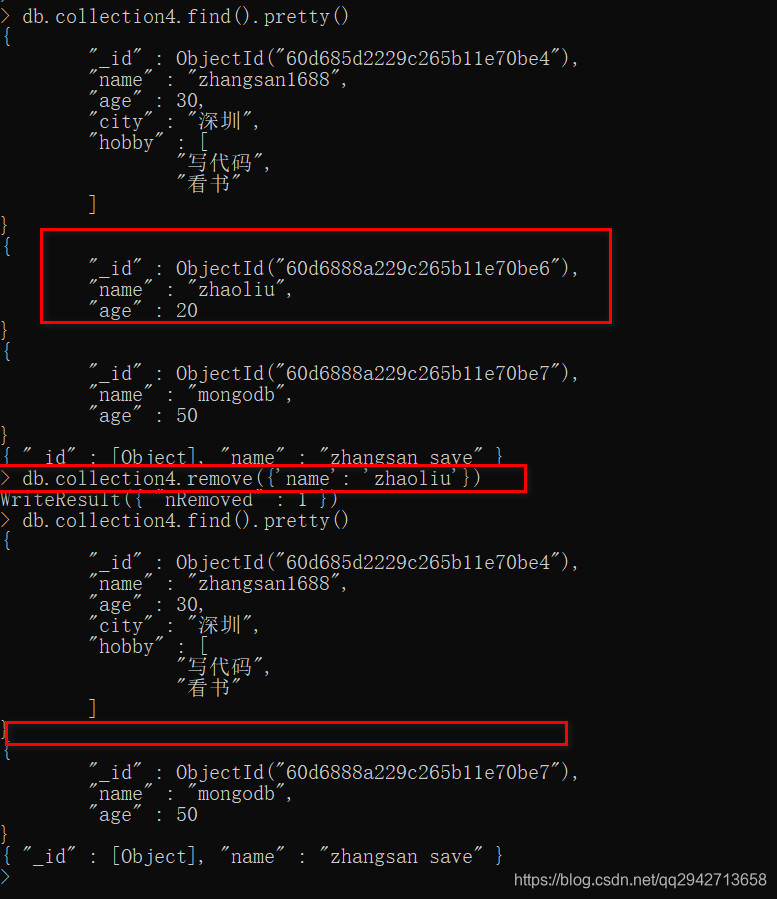
4.删除文档
db.collection.remove( <query>, <justOne> )
参数说明:
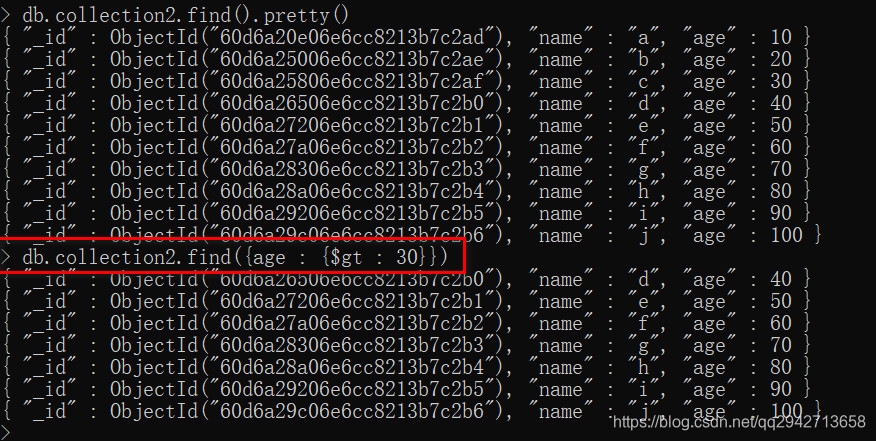
1.大于(>): $gt
db.collection2.find({age : {$gt : 30}})
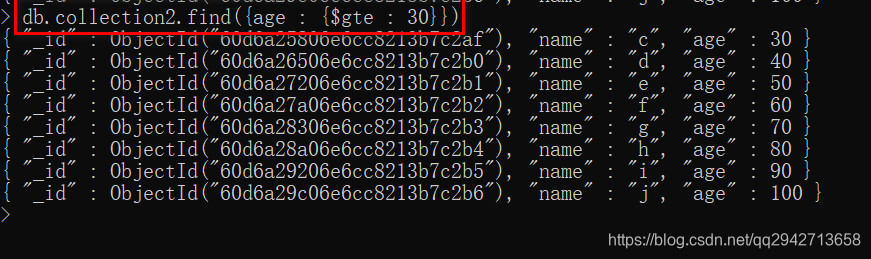
2.大于等于(>=): $gte
db.collection2.find({age : {$gte : 30}})
3.小于(<):$lt
db.collection2.find({age : {$lt : 20}})

4.小于等于(<=):$lte
db.collection2.find({age : {$lte : 20}})

5.$lt 和 $gt
db.collection2.find({age : {$gt : 30, $lt : 60,}})

| 运算符 | 作用 |
|---|---|
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
| $ne | 不等于 |
| $in | in |
| $nin | not in |
MongoDB 中可以使用的类型如下表所示:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
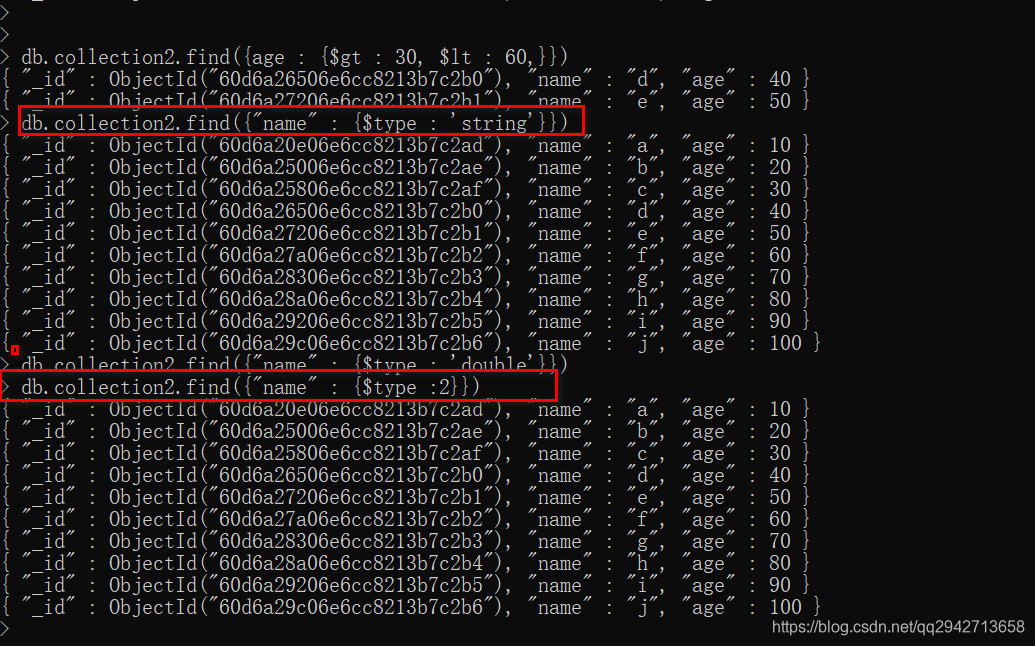
db.collection2.find({"name" : {$type :2}})
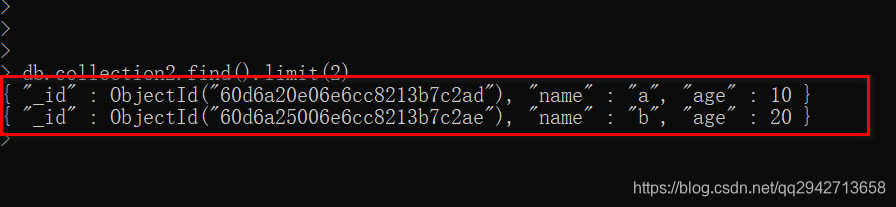
1.limit()读取记录的条数
db.COLLECTION_NAME.find().limit(NUMBER)
2.skip()跳过的记录条数
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)

sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
1.升序排序
db.COLLECTION_NAME.find().sort({KEY:1})
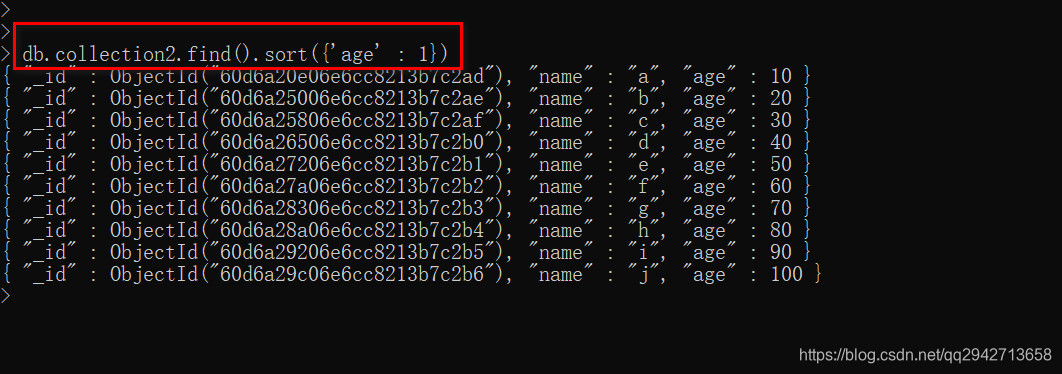
2.降序排序
db.COLLECTION_NAME.find().sort({KEY:-1})
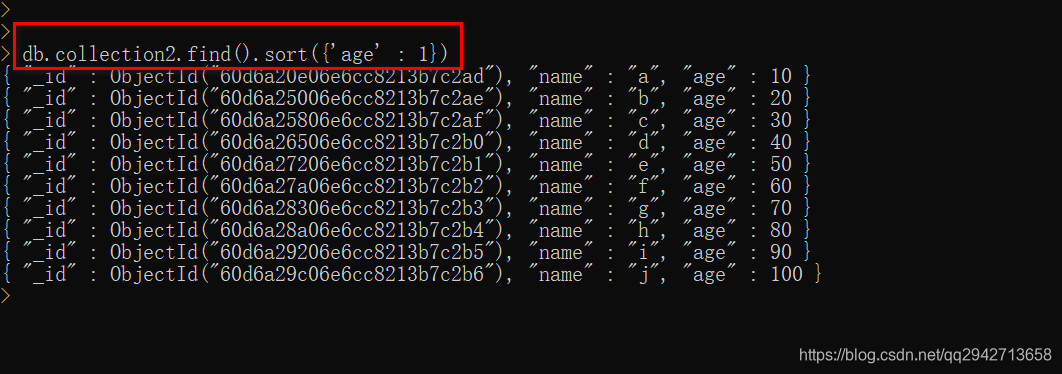
默认情况下,集合中的_id字段就是索引,我们可以通过getIndexes()方法来查看一个集合中的索引:
db.sang_collect.getIndexes()
结果如下:
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "sang.sang_collect"
}
]
我们看到这里只有一个索引,就是_id。
现在我的集合中有10000个文档,我想要查询x为1的文档,我的查询操作如下:
db.sang_collect.find({x:1})
这种查询默认情况下会做全表扫描,我们可以用上篇文章介绍的explain()来查看一下查询计划,如下:
db.sang_collect.find({x:1}).explain("executionStats")
结果如下:
{
"queryPlanner" : {
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 15,
"totalKeysExamined" : 0,
"totalDocsExamined" : 10000,
"executionStages" : {
"stage" : "COLLSCAN",
"filter" : {
"x" : {
"$eq" : 1.0
}
},
"nReturned" : 1,
"executionTimeMillisEstimate" : 29,
"works" : 10002,
"advanced" : 1,
"needTime" : 10000,
"needYield" : 0,
"saveState" : 78,
"restoreState" : 78,
"isEOF" : 1,
"invalidates" : 0,
"direction" : "forward",
"docsExamined" : 10000
}
},
"serverInfo" : {
},
"ok" : 1.0
}
结果比较长,我摘取了关键的一部分。我们可以看到查询方式是全表扫描,一共扫描了10000个文档才查出来我要的结果。实际上我要的文档就排第二个,但是系统不知道这个集合中一共有多少个x为1的文档,所以会把全表扫描完,这种方式当然很低效,但是如果我加上 limit,如下:
db.sang_collect.find({x:1}).limit(1)
此时再看查询计划发现只扫描了两个文档就有结果了,但是如果我要查询x为9999的记录,那还是得把全表扫描一遍,此时,我们就可以给该字段建立索引,索引建立方式如下:
db.sang_collect.ensureIndex({x:1}) //该方法在新版本中已经废弃
1表示升序,-1表示降序。当我们给x字段建立索引之后,再根据x字段去查询,速度就非常快了,我们看下面这个查询操作的执行计划:
db.sang_collect.find({x:9999}).explain("executionStats")
这个查询计划过长我就不贴出来了,我们可以重点关注查询要耗费的时间大幅度下降。
此时调用getIndexes()方法可以看到我们刚刚创建的索引,如下:
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "sang.sang_collect"
},
{
"v" : 2,
"key" : {
"x" : 1.0
},
"name" : "x_1",
"ns" : "sang.sang_collect"
}
]
我们看到每个索引都有一个名字,默认的索引名字为字段名_排序值,当然我们也可以在创建索引时自定义索引名字,如下:
db.sang_collect.ensureIndex({x:1},{name:"myfirstindex"})
此时创建好的索引如下:
{
"v" : 2,
"key" : {
"x" : 1.0
},
"name" : "myfirstindex",
"ns" : "sang.sang_collect"
}
当然索引在创建的过程中还有许多其他可选参数,如下:
db.sang_collect.ensureIndex({x:1},{name:"myfirstindex",dropDups:true,background:true,unique:true,sparse:true,v:1,weights:99999})
关于这里的参数,我说一下:
1.
name表示索引的名称
2.dropDups表示创建唯一性索引时如果出现重复,则将重复的删除,只保留第一个
3.background是否在后台创建索引,在后台创建索引不影响数据库当前的操作,默认为false
4.unique是否创建唯一索引,默认false
5.sparse对文档中不存在的字段是否不起用索引,默认false
6.v表示索引的版本号,默认为2
7.weights表示索引的权重
此时创建好的索引如下:
{
"v" : 1,
"unique" : true,
"key" : {
"x" : 1.0
},
"name" : "myfirstindex",
"ns" : "sang.sang_collect",
"background" : true,
"sparse" : true,
"weights" : 99999.0
}
使用createIndex()方法创建索引
db.collection.createIndex(keys, options)
语法中 key值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
createIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
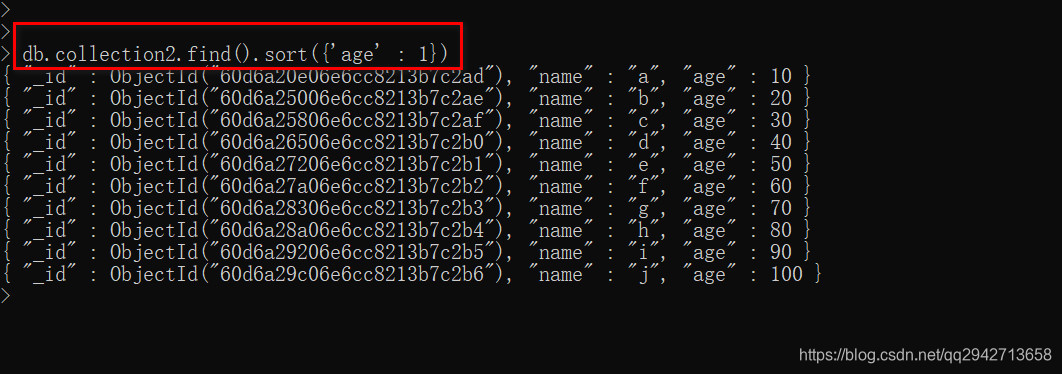
getIndexes()可以用来查看索引,我们还可以通过totalIndexSize()来查看索引的大小,如下:
db.sang_collect.totalIndexSize()
1.聚合
聚合主要用来处理数据(平均值、求和等),并返回计算结果。
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
2.聚合管道
聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
聚合框架中常用的几个操作:
统计colection2集合中记录条数
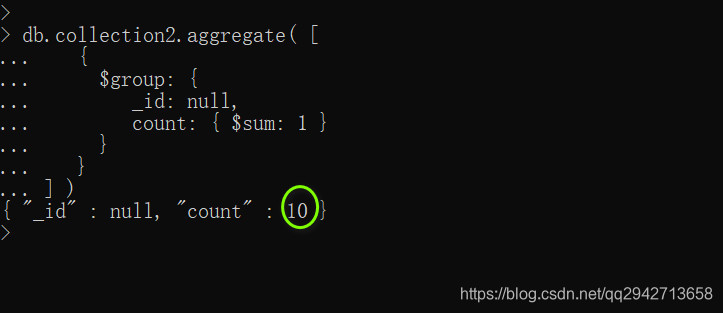
统计collection2集合age的和
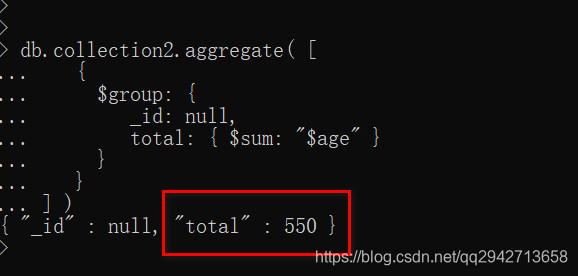
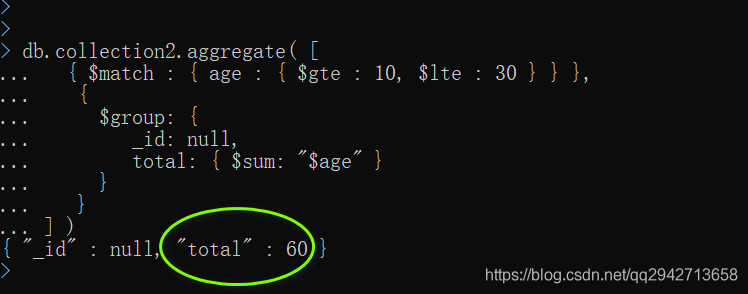
统计collection2集合中age>=10且=30的age的和
1.复制:
复制是将数据同步在多个服务器的过程
2. 复制原理
MongoDB复制至少需要2个节点,其中1个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。常见的搭配的方式:一主一从、一主多从
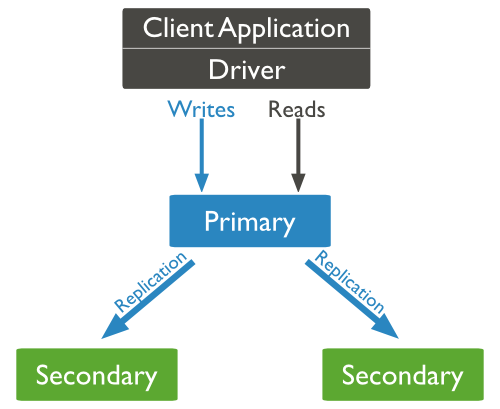
以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点时,主节点与从节点交互保证数据一致性。
1.需求
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我么就可以在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
2.为什么使用分片
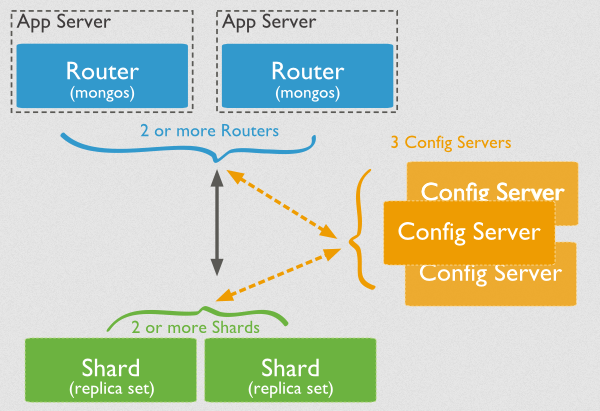
3.MongoDB分片
分片集群结构
mongodump -h dbhost -d dbname -o dbdirectory
MongoDB 所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
需要备份的数据库实例,例如:test
备份的数据存放位置,例如:c:\data\dump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据。
mongodump 命令可选参数列表如下所示:
| 语法 | 描述 | 实例 |
|---|---|---|
| mongodump --host HOST_NAME --port PORT_NUMBER | 该命令将备份所有MongoDB数据 | mongodump --host runoob.com --port 27017 |
| mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY | mongodump --dbpath /data/db/ --out /data/backup/ | |
| mongodump --collection COLLECTION --db DB_NAME | 该命令将备份指定数据库的集合。 | mongodump --collection mycol --db test |
mongodump
执行以上命令后,客户端会连接到ip为 127.0.0.1 端口号为 27017 的MongoDB服务上,并备份所有数据到 bin/dump/ 目录中。
了解MongoDB的运行情况,并查看MongoDB的性能。这样在大流量得情况下可以很好的应对并保证MongoDB正常运作。MongoDB中提供了mongostat 和 mongotop 两个命令来监控MongoDB的运行情况。
1.mongostat 命令
mongostat是mongodb自带的状态检测工具,在命令行下使用。它会间隔固定时间获取mongodb的当前运行状态,并输出。如果你发现数据库突然变慢或者有其他问题的话,你第一手的操作就考虑采用mongostat来查看mongo的状态。
启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录, 然后输入mongostat命令,
D:\set up\mongodb\bin>mongostat
2.mongotop 命令
mongotop也是mongodb下的一个内置工具,mongotop提供了一个方法,用来跟踪一个MongoDB的实例,查看哪些大量的时间花费在读取和写入数据。 mongotop提供每个集合的水平的统计数据。默认情况下,mongotop返回值的每一秒。
启动你的Mongod服务,进入到你安装的MongoDB目录下的bin目录, 然后输入mongotop命令,如下所示:
D:\set up\mongodb\bin>mongotop
1.关系
MongoDB 中的关系可以是:
下面以用户的地址为例
(1)嵌入式关系
缺点:如果用户和用户地址在不断增加,数据量不断变大,会影响读写性能
查询
db.users.findOne({"name":"Tom Benzamin"},{"address":1})
(2)引用关系
这种方法需要两次查询,第一次查询用户地址的对象id(ObjectId),第二次通过查询的id获取用户的详细地址信息
var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
2.查询分析
查询分析常用函数explain()和hint()
(1)explain 操作提供了查询信息,使用索引及查询统计等。有利于我们对索引的优化。
创建gender和user_name的索引
db.users.ensureIndex({gender:1,user_name:1})
使用explaing
db.users.find({gender:"M"},{user_name:1,_id:0}).explain()
返回结果如下: